Литература
Справочная информация
Для учебы
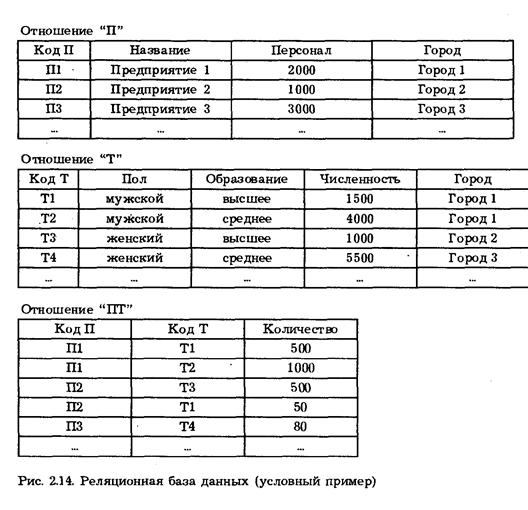
Модели данных ГИСМодели данныхКак уже отмечалось, различаются три типа СУБД по общему виду Структуры представления данных - т. н. моделей данных: иерархические, сетевые и реляционные. Среди них наибольшее распространение Получили последние. В настоящее время иерархические и сетевые модели значительно уступают реляционным по количеству реализации в коммерческих СУБД, поэтому ограничимся здесь их кратким описанием, отсылая систематического читателя к специальной литературе I. В иерархических моделях данные организованы в виде иерархической структуры (имеющей вид "дерева"), в которой исходные элементы порождают другие элементы, причем эти элементы в свою очередь порождают следующие элементы и т. д. Элементы (поля), связывающие верхние и нижние уровни иерархии, отражают принципиальную особенность иерархической организации данных: каждая запись приобретает смысл лишь тогда, когда она рассматривается в определенном контексте. Иными словами, любой подчиненный элемент не может существовать без своего предшественника по иерархии. Как указывается в, иерархические модели БД чрезвычайно привлекательны для целей географических исследований, так как обеспечивают естественный и адекватный метод информационного моделирования реальных, иерархически организованных географических объектов: Экономических районов и природных ландшафтов, систем расселения и гидрографических сетей, систем обслуживания и административно-территориальных единиц. В то же время, несмотря на то, что иерархическая модель по самой своей сути ориентирована на организацию данных в территориальном разрезе, любые другие выборки (отраслевые, классификационные) хотя и возможны, но связаны со значительными затратами времени на поиск необходимой информации. В этом состоит основной недостаток иерархической модели данных. II. Сетевые модели допускают любые группировки данных и произвольные связи между ними, и в этом смысле являются универсальными. Однако структура сетевой модели обычно намного сложнее иерархической, и для переходов (навигации) в такой БД необходимы дополнительные вычислительные ресурсы. В отличие от иерархической, в сетевой структуре можно легко производить удаление устаревшей информации без риска потерять нужные сведения. "Узкое место" сетевого подхода состоит в необходимости выбора стратегии поиска необходимой информации (эта проблема аналогична нахождению кратчайшего пути между двумя пунктами сложной и разветвленной сети), что сопряжено с трудностями программного и вычислительного характера. Несмотря на отмеченные недостатки, иерархическая и сетевая модели будут существовать и использоваться еще в течение достаточно длительного времени, так как на создание соответствующих БД затрачены значительные средства и здесь уже накоплен большой опыт. III. Реляционная модель базы данных была предложена в 1970 году американским ученым Коддом. Она основана на представлении данных в виде отношений между ними. При этом представление этих отношений подвергается нормализации - пошаговому процессу приведения к примерной табличной форме, причем информация об отношениях сохраняется полностью. Представление данных в виде двухмерных таблиц является естественным и хорошо воспринимается пользователями. Под таблицами в данном случае понимают прямоугольные массивы, обладают следующими свойствами: элементу данных соответствует единственный вход в таблицу; в каждой из колонок таблицы располагаются :элементы некоторого вида; каждой колонке присваивается имя; не допускаются строки таблиц с совпадающими значениями всех колонок и строки таблиц могут просматриваться в любой последовательности. Отношения в реляционной модели базы данных представлений таблицами, в которых каждая из строк содержит значения свойств (или атрибутов), которыми обладает некоторый объект данного типа; Каждый из столбцов соответствует множеству значений, которому присущ некоторый атрибут этою типа. Совокупность значений одного атрибута (соответствующая столбцу таблицы) называется его Доменом. Для описания отношений и манипуляций над ними в реляционной модели данных используется строгий математический язык, основанный на алгебре отношений и исчислении отношений. При этом возможны три уровня сопряжения пользователя с базой данных: на высшем уровне пользователь формулирует свои запросы в терминах реляционного исчисления, определяя, какие новые отношения он желает образовать из соотвествующих; на среднем уровне запрос формулируется как последовательность операций реляционной алгебры, выполняемых над отношениями; на самом низком уровне пользователь определяет шаги получения некоторого Кортежи отношения (кортежами называются Строки таблицы отношения), т. е. полностью управляет поиском данных в базе данных. приведен условный экономико-географический пример реляционной базы данных, предложенный И. А.Портянским и частично адаптированный нами для целей наглядности (см. Рис. 2.14). Как видно из Рис. 2.14„ в этой условной реляционной базе данных отношение "П" содержит сведения о промышленных предприятиях. Отношение "Т" содержит данные о половом и образовательном составе трудовых ресурсов в городах региона. Отношение "ПТ" содержит сведения о том, какие трудовые ресурсы заняты на том или ином предприятии; так, первые кортежи этого отношения свидетельствуют, что на Предприятии 1 в Городе 1 занято 500 мужчин с высшим образованием, со средним, проживающих в этом же городе. Отметим, что фигурирующие в базе данных значения атрибутов "Город" взяты из основного домена всех вероятных названий городов, который в данном случае специально не задан. Заметим также, что все отношения имеют какой-либо общий домен.
Это обстоятельство наглядно демонстрирует основное свойство реляционных моделей данных - связи между кортежами разных отношений прослеживаются только в одинаковых значениях атрибутов, извлеченных из общего домена. Тот факт, например, что предприятие П1 и трудовые ресурсы Т1 находятся в одном городе, отражается одинаковыми значениями (Город 1) в столбцах "Город" двух указанных кортежей. Таким образом, реляционный подход реализует оригинальную идею - рассматривать связи между объектами как специальные типы объектов. Следовательно, вся информация в базе данных, как "объекты", так и "связи", могут быть представлены в единой унифицированной форме. Этим преимуществом не обладают иерархический и сетевой подходы. Программные средства СУБДВ настоящее время в информационных системах, функционирующих в ПЭВМ, совместимых с IBM PC, большое распространение получили так называемые DBASE-подобные системы управления базами данных (СУБД), которые используют в качестве основных рабочих файлы с расширением. dbf. Известно по крайней мере три вида таких СУБД (dBASE, FoxBase и Clipper), однако версий систем и их адаптированных вариантов гораздо больше. Для пользователей существенным является то, что отличаясь между командными языками и форматом индексных файлов, все эти люди используют одни и те же файлы. dbf, формат которых стал по существу своеобразным стандартом баз данных. Во всех dBASE-подобных базах данных фактически используется реляционный подход к организации данных, т. е. каждый файл dbf представляет собой двухмерную таблицу, которая состоит из фиксированного числа столбцов и переменного числа строк (записей). В терминах, используемых в технической документации, каждому столбцу соответствует по одному из пяти типов (N - числовое, С - символьное, D - дата, L - логическое или М - примечание), а каждой строке - запись фиксированной данной, состоящая из фиксированного числа полей. Следует отметить, что все большее распространение получают данные с другим форматом файлов - например, Paradox, Clarion, de_Vista. Эти системы представляются как универсальные средства для создания и ведения персональных баз данных в любой предметной области. Однако необходимо иметь ввиду, что указанные СУБД являются лишь инструментами для разработки и эксплуатации прикладных информационных систем, и для их использования необходимо, как правило, реализовать всю технологическую цепочку подготовки информации проекта: алгоритмизация – программирование – отладка - сопровождение. И хотя почти все эти системы содержат ряд технологических "программирования без программиста" (типа "Ассистента", они часто не исчерпывают многочисленных возможностей и всегда удовлетворяют конечного пользователя. Особое место занимает пакет Access различных версий (Open Access, DOS, Windows Access). Это мощная интегрированная система, в состав которой входят: реляционная СУБД, электронные таблицы, текстовый редактор, средства для организации коммуникаций и многое другое. Например, эта система может манипулировать не только числовой и текстовой информацией, но и графическими образами (рисунками, фотографиями), звуковыми фрагментами и видеоклипами. С помощью пакета Access можно создать таблицу, содержащую до 2 миллиардов записей и 255 полей. Следует отметить, что большинство коммерческих пакетов ГИС имеют интерфейс с перечисленными СУБД, поддерживают импорт и экспорт данных в форматах наиболее распространенных СУБД и даже организуют собственное хранение атрибутивных данных (например, в ASCII-таблицах)
Модели данных ГИС - 3.2 out of
5
based on
6 votes
|
Материалы по темам:Основи картографії |